How can CLI usage be measured, while respecting end-user’s privacy?
Originally posted on dev.to
The CLI is a critical part of the developer experience. Often, it’s the first interface for developers to interact with your product. However, with Open Source products, it’s difficult to know if and how end-users are using your product. Even though telemetry data might be very interesting for the product team, it’s important to respect the end-user’s privacy; we need to ensure that no sensitive data is collected.
Only collect data on how end-users use the CLI to interact with your product, and stay inside those boundaries.
In this post, I’ll explain how we implemented a telemetry collection system for the PACE CLI. But first, let me briefly introduce what PACE is.
Enforcing data policies on data processing platforms
The goal of PACE (Policy As Code Engine), is to ensure that data consumers can only view data in such a way, that was defined in the Data Policy. This is done by defining filters and transforms on fields in the data, and translating this Data Policy into a SQL view. Various processing platforms, such as Snowflake, BigQuery, and PostgreSQL are supported at the moment.
Why does the product team need telemetry?
Since PACE is an Open Source product, we don’t have any insight into how end-users are using the product. We don’t know which features are used, and which features are not. This makes it more difficult for the product team to prioritize specific features. No runtime environment is the same, therefore, it’s impossible for us to go over every scenario. Telemetry data can help us to understand how the CLI and how the product behave, and what error codes may occur.
Therefore, we decided to implement a telemetry collection system for the CLI.
Determining the type of data that should be collected
As said before, we want to respect the privacy of the end-user and their organization. The CLI for PACE is structured as follows:
pace <verb> <noun> [possible other sub commands] [options]
The CLI is built in Go using cobra, a popular CLI framework. The
cool thing about cobra, is that has hooks for various lifecycle phases of the CLI execution. This allows us to define a PersistentPreRunE, which is executed before every command, even if that command is a subcommand. This way, the actual command path, hence the verb and noun (and possible
other sub commands) can be collected. Another benefit of using this approach, is that no arguments, nor any flags (i.e. command options) are collected. Even though the command options are often interesting for the product team, we have decided not to include this, as this is on the edge of
what we consider to be sensitive data.
Now that we know the command path, we still need to know what the exit code will be of the command. I’m writing will be, as the actual exit code won’t be known until the program has finished. Though we cannot perform any tasks after the program has finished, and a CLI is not a continuous running application. Therefore, all errors that may occur anywhere in the application, are propagated across the entire call stack.
The root command (i.e. pace) has a RunE function, which returns the Go error. This error can be mapped in a command finalization function onto an exit code. Furthermore, this finalization function is also responsible for keeping track of the telemetry.
Summarizing, this looks as follows in our CLI (simplified). The finalization function will be discussed later.
package main
import (
"github.com/spf13/cobra"
"os"
)
// commandPath is set on each command execution. It needs to be a global variable, as cobra run functions
// only allow side effects
var commandPath string
func main() {
rootCmd := &cobra.Command{
Use: "pace",
PersistentPreRunE: rootCmdPreRun,
}
commandError := rootCmd.Execute()
if commandError != nil {
os.Exit(1)
}
}
func rootCmdPreRun(cmd *cobra.Command, _ []string) error {
commandPath = cmd.CommandPath()
return nil
}
Keeping track of telemetry across multiple CLI invocations
The CLI is a stateless application. This means that every time the CLI is executed, it starts from scratch. This means that we cannot keep track of telemetry data in memory, as this data will be lost after the CLI has finished. Therefore, we need to persist the telemetry data somewhere. A local file is the solution here, and an extra added benefit, is that it’s completely transparent of the data that is collected.
For the PACE CLI, the data is stored in ~/.config/pace/telemetry.yaml. An example file:
metric_points:
pace get data-policy: # the command path
0: # the command exit code
cumulative_count: 2 # the cumulative number of times this has occurred since the telemetry.yaml file was created
1: # a non-successful command execution
cumulative_count: 1 # occurred once.
pace list processing-platforms:
0:
cumulative_count: 1
pace list tables:
0:
cumulative_count: 2
pace version:
0:
cumulative_count: 17
cli_version: v1.16.0
operating_system: darwin # macOS
id: 36be4c46-4e1b-431d-b9db-1b315f537a85 # a random identifier of this cli instance.
The structure is pretty much self-explanatory, but in summary, we collect the amount of times a specific command was executed, and what the exit code was. Furthermore, we also collect the CLI version, the operating system, and assign a random identifier to your specific CLI instance, in order to be able to determine the amount of unique users. This is a random UUID, which is not linked in any way to you, your organization, or your machine deterministically (feel free to take a look at the CLI source code).
Sending the telemetry data to getSTRM
Now that the CLI keeps track of telemetry data, it needs to send it to getSTRM. As a visualization layer on top of this data, we use Grafana Cloud, which has a built-in Prometheus (de facto cloud native standard for metrics collection and storage) and Graphite (time-series metrics database, much older than Prometheus) server, that we can send the data to. Although, we thought that was the case. Turned out we had incorrect assumptions on Grafana Cloud providing a Prometheus Pushgateway (Prometheus has a pull based architecture, meaning it’s designed to scrape applications for their metrics, but that is impossible in our scenario). Unfortunately, this was not documented in the Grafana Cloud docs, and we found out the hard way. We learned:
Prometheus
remote_write!= Prometheus Pushgateway
Grafana offered a remote_write endpoint for Prometheus to send data to if configured in agent mode, which is a way to collect data from an isolated runtime environment of applications exposing Prometheus style metrics, and forwarding it to another Prometheus instance (which is Grafana Cloud).
Therefore, we’ve decided to try Graphite, as Graphite has a push based architecture, which means we can send data to Grafana Cloud. After some experimentation with cURL, we didn’t see any data in Grafana Cloud in the graphite data source which was configured, even though the HTTP response of
our request we sent with cURL was successful. We started thinking that none of the metric endpoints for Grafana Cloud were working, after which I decided to take a look at the Prometheus data source for our Grafana Cloud account.
And there it was, the data that was sent to Graphite, was visible in the Prometheus data source, as a graphite_tagged metric (we filed a question at Grafana support to elaborate on this). As strange as this was, we decided to go with this approach, as it prevented us from having to set up our own
monitoring stack.
Actually sending the telemetry data to getSTRM
After the challenge with getting data into Grafana Cloud, we were able to draw the entire architecture of the telemetry collection system.
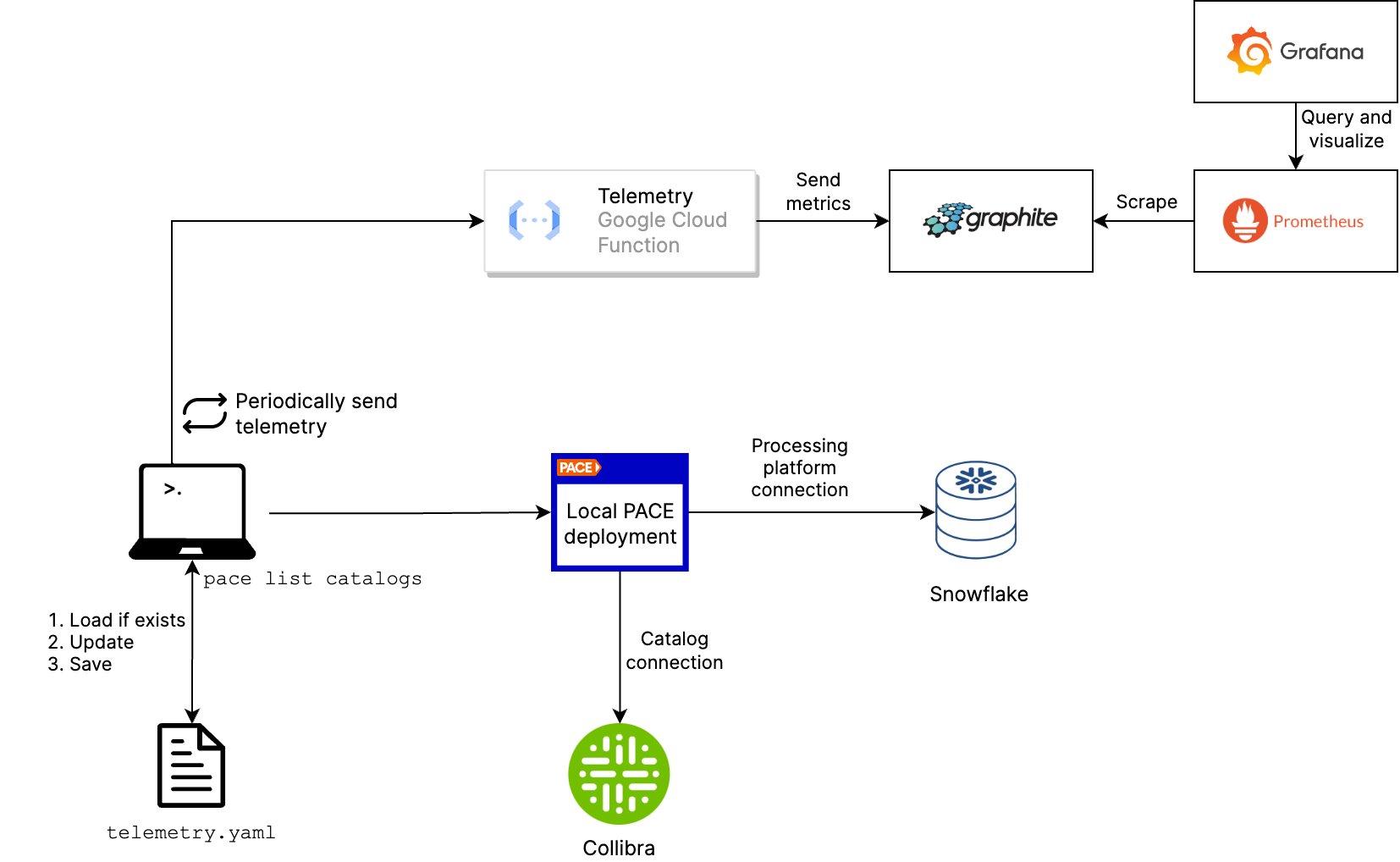
As you can see in the diagram, the CLI periodically sends the collected telemetry from the file to the Google Cloud Function. As requests to Graphite in Grafana Cloud need an API key, a cloud function is a proper way to protect the API key from being exposed.
The role of the Cloud Function is merely to transform the incoming telemetry data into the format that Graphite expects. Each (sub)command is translated into a tag in Graphite (which corresponds with a label in Prometheus), as well as the cli_version, operating_system, id and exit code.
The end result of this entire process is a Grafana dashboard, of which a screenshot is shown below.
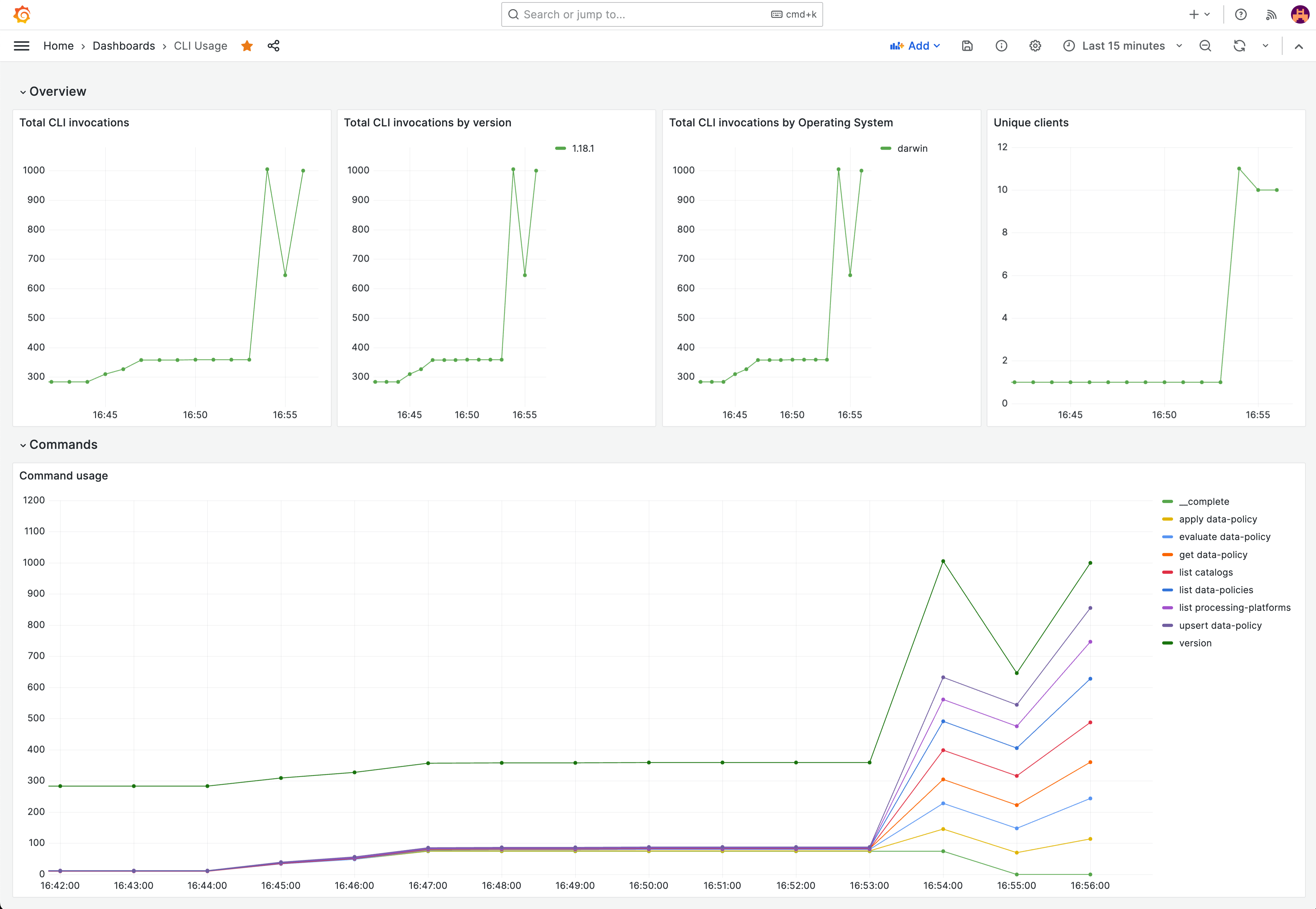
Conclusion
In this post, I’ve explained how we implemented a telemetry collection system for the PACE CLI. As trivial as the problem may seem, it was a challenge to get the data into Grafana Cloud. In the end, we’ve managed to create a system that respects the end-user’s privacy, while still providing valuable insights to the product team.
What do you think? Drop us a line in our Slack community!